Indexing in Cassandra: Strategies for Efficient Data Retrieval

Apache Cassandra is designed for high scalability and fault tolerance, capable of handling massive amounts of data across distributed clusters. Effective indexing is crucial to optimizing performance in such a distributed system. This blog explores various indexing strategies in Cassandra, including primary keys, secondary indexes, materialized views, and custom indexing solutions, along with a detailed explanation of partition keys, composite keys, and clustering columns with fresh examples and visual aids.
1. Overview of Indexing in Cassandra
Indexing in Cassandra is essential for efficient data retrieval and requires a different approach compared to traditional relational databases due to its distributed nature.
1.1. Primary Key and Clustering Columns
-
Primary Key: The primary key in Cassandra is a combination of the partition key and clustering columns. The partition key determines the node where the data is stored, while clustering columns define the order of data within the partition. This structure allows Cassandra to quickly locate and access rows based on key values.
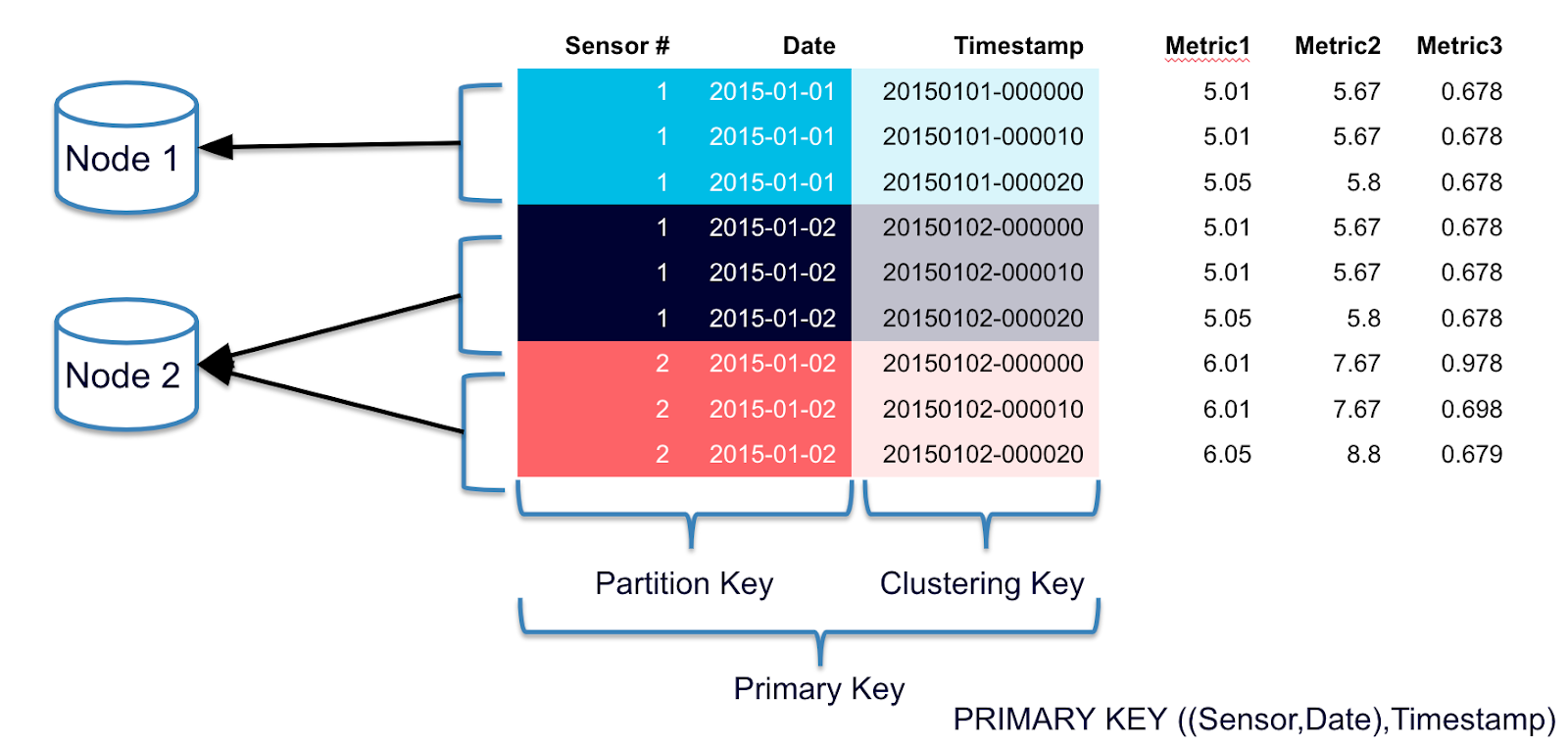
Figure 1: Primary Key and Clustering Columns in Cassandra -
Clustering Columns: Clustering columns are used to sort data within a partition. They enable efficient range queries and ordered retrieval, making it possible to fetch data in a specific sequence based on these columns.
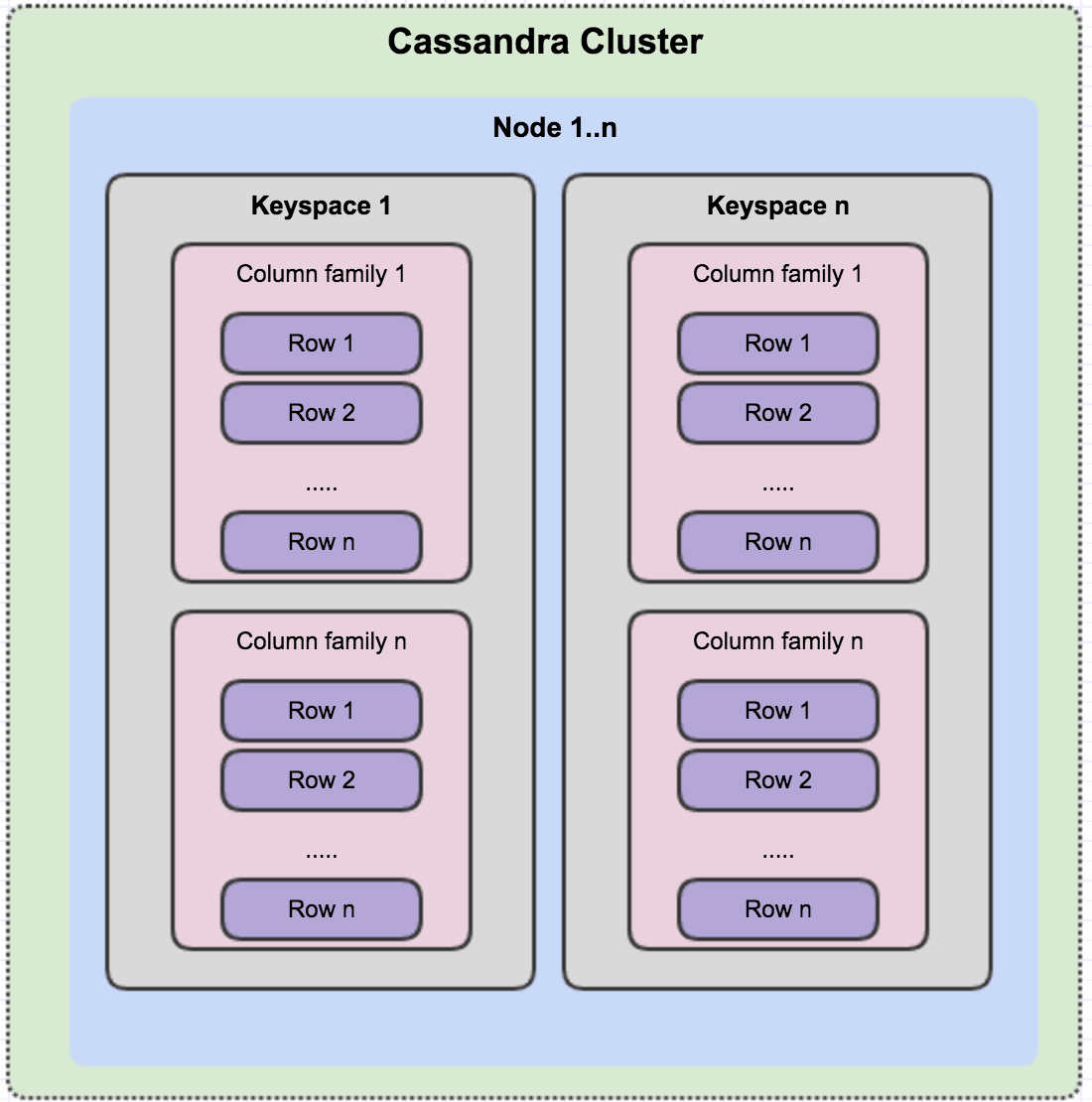
Figure 2: Data Sorting with Clustering Columns

2. Secondary Indexes
Secondary indexes allow queries on columns that are not part of the primary key. While they provide flexibility, they also come with performance considerations.
2.1. Overview of Secondary Indexes
-
Structure: Secondary indexes create a separate index table where the indexed column’s values are mapped to the rows in the base table. Queries using the indexed column access this index table to find relevant rows quickly.
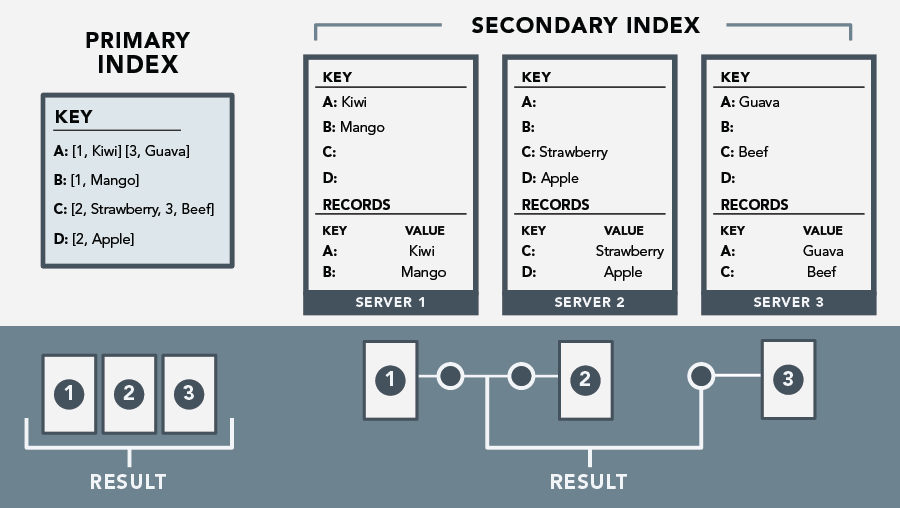
Figure 3: Structure of Secondary Indexes -
Advantages:
- Flexibility: Facilitates querying on columns outside the primary key.
- Simplicity: Easy to implement with minimal schema changes.
-
Limitations:
- Performance Overheads: Can introduce performance costs, especially with high-cardinality columns or large datasets, due to the need for index maintenance with each write operation.
- Best Suited for Specific Scenarios: More effective for low-cardinality columns and read-heavy workloads.

2.2. Use Cases and Best Practices
- Low-Cardinality Columns: Secondary indexes are effective for columns with a limited number of distinct values (e.g., flags or category labels).
- Read-Intensive Workloads: Best for scenarios where read operations are frequent and writes are less frequent.
3. Materialized Views
Materialized views provide pre-computed views of data, optimizing access based on specific query patterns.
3.1. Overview of Materialized Views
-
Structure: Materialized views are tables that automatically reflect changes from the base table, tailored to support specific queries. They provide optimized access to data.
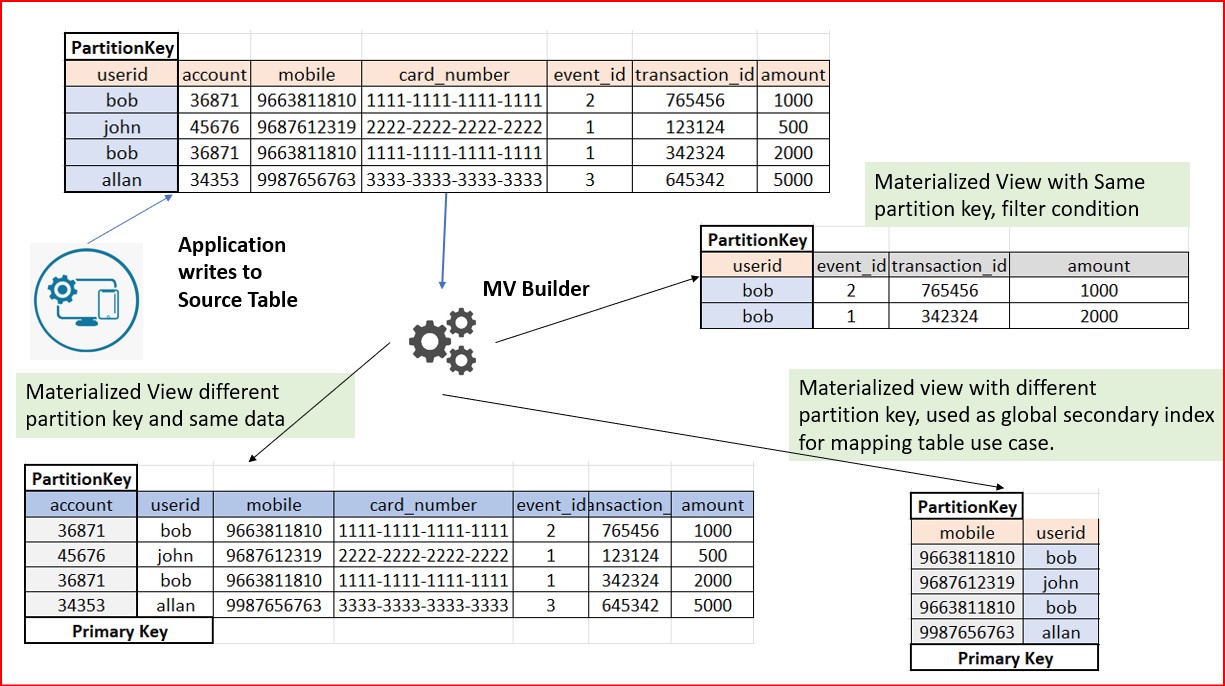
Figure 4: Structure of Materialized Views -
Advantages:
- Optimized Query Performance: Directly supports specific query patterns for faster access.
- Automatic Synchronization: Maintained automatically, reducing the need for manual updates.
-
Limitations:
- Write Impact: Updates to the base table can affect write performance due to the need to update all materialized views.
- Schema Complexity: Adds complexity to schema design and requires careful planning.

3.2. Use Cases and Best Practices
- Query Optimization: Use materialized views for optimizing frequently accessed queries.
- Schema Planning: Design materialized views around the most critical queries to balance read and write performance.
4. Custom Indexing Strategies
Cassandra supports custom indexing solutions for advanced needs, including external indexing systems and custom logic.
4.1. Custom Indexing Solutions
- External Indexing Systems: Integration with systems like Elasticsearch can provide advanced search capabilities and indexing features.
- Custom Logic: Implement custom indexing strategies at the application level to meet specific performance requirements.
4.2. Best Practices
- Assess Requirements: Choose the right indexing strategy based on your application’s query patterns, data volume, and performance needs.
- Monitor and Optimize: Continuously monitor and adjust indexing strategies as your application evolves.
5. Partition Key vs. Composite Key vs. Clustering Columns in Cassandra
Understanding partition keys, composite keys, and clustering columns is essential for efficient data modeling in Cassandra.
5.1. Partition Key
The partition key determines how data is distributed across the cluster. It is hashed to ensure even distribution among nodes.
Example:
CREATE TABLE library (
book_id text,
title text,
author text,
genre text,
published_year int,
PRIMARY KEY (book_id, author)
);
Here, book_id is the partition key. All records with the same book_id are stored on the same node.
5.2. Composite Key
A composite key includes multiple columns in the partition key, allowing for finer-grained data distribution.
Example:
CREATE TABLE library (
book_id text,
title text,
author text,
genre text,
published_year int,
PRIMARY KEY ((book_id, author), published_year)
);
In this schema, (book_id, author) forms the composite partition key, and published_year is a clustering column. This design partitions data based on both book_id and author, while ordering data within each partition by published_year.
5.3. Clustering Columns
Clustering columns sort data within a partition, enabling efficient range queries and ordered retrieval.
Example:
CREATE TABLE library (
book_id text,
title text,
author text,
genre text,
published_year int,
PRIMARY KEY (book_id, genre, published_year)
);
Here, genre and published_year are clustering columns, sorting data within each book_id partition by genre and published_year.
6. Conclusion
Indexing in Cassandra is key to optimizing data retrieval and ensuring efficient performance in distributed environments. By understanding and applying primary keys, secondary indexes, materialized views, and custom indexing strategies effectively, you can enhance the performance and scalability of your Cassandra-based applications. Utilizing partition keys, composite keys, and clustering columns appropriately is vital for designing effective data models.
Leverage these indexing strategies based on your application’s specific needs to achieve optimal performance and efficient data management.