Indexing in Relational vs Non-Relational Databases
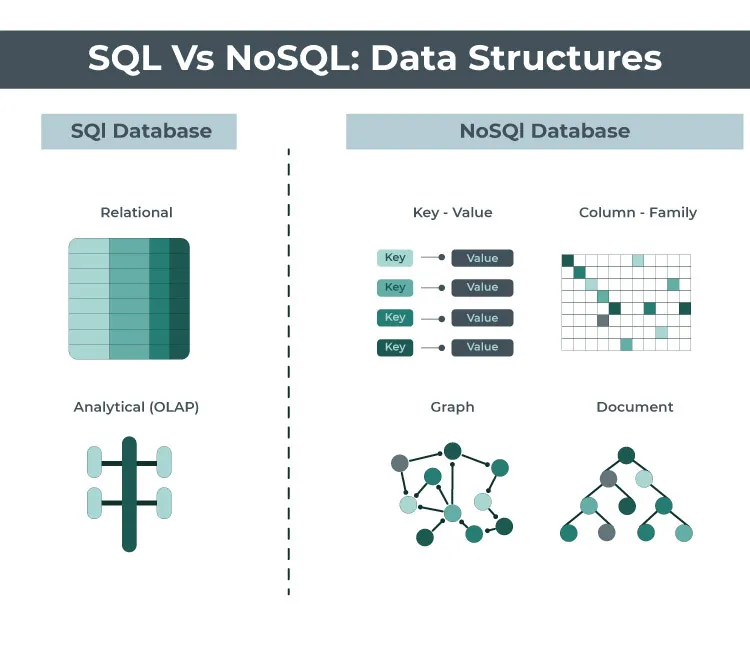
When it comes to optimizing database performance, indexing is a fundamental technique used to speed up data retrieval operations. However, the way indexing is implemented can vary significantly between relational databases (RDBMS) and non-relational databases (NoSQL). This blog explores the key differences and considerations for indexing in these two types of databases.
1. Indexing in Relational Databases
In relational databases, indexes are crucial for improving the efficiency of query operations. They work by creating a sorted copy of specified columns, which allows the database to quickly locate the rows that match a given query. Here’s how indexing typically works in relational databases:
-
Primary Key Indexes: Every table in a relational database usually has a primary key column, which is automatically indexed. This index ensures that each row can be quickly identified using the primary key value. The primary key index is usually a B-tree structure, which supports efficient lookups, insertions, and deletions.
-
Secondary Indexes: In addition to the primary key, other columns can be indexed to optimize query performance. For example, if a database frequently searches for articles by their title, an index on the title column can make these searches faster. Secondary indexes can also be composite, involving multiple columns, to handle more complex queries. For instance, an index on both
author_idandpublished_atcan improve performance for queries that involve both columns. -
Trade-offs: While indexes speed up read operations, they can slow down write operations. Adding, updating, or deleting rows requires updating the indexes as well. Therefore, it’s important to balance the need for fast queries with the potential impact on write performance.
2. Indexing in Non-Relational Databases
Non-relational databases, or NoSQL databases, use different indexing strategies due to their flexible schema and varying data models. Here’s a look at how indexing is handled in NoSQL databases:
-
Document Stores: In document-based NoSQL databases (like MongoDB), indexes can be created on any field within documents. This allows for efficient querying of nested fields and arrays. For example, if a collection of documents includes user profiles, an index on the
emailfield can speed up lookups for specific users. -
Column Stores: Column-family stores (like Cassandra) use a different approach. Indexes in column stores are often designed to optimize read performance across wide column families. For example, Cassandra uses a data structure called a “SSTable” (Sorted String Table) for indexing, which supports efficient reads and writes.
-
Key-Value Stores: In key-value stores (like Redis), indexing is typically straightforward. The primary key acts as the index, allowing for rapid retrieval of values associated with that key. Additional indexing strategies may be employed based on specific use cases.
-
Graph Databases: Graph databases (like Neo4j) index nodes and relationships to optimize traversals. Indexes in graph databases help in quickly locating nodes or relationships based on properties, which is crucial for graph traversals and queries.
3. Comparing Indexing Strategies
-
Schema Flexibility: Relational databases enforce a fixed schema, which means indexes are created based on predefined columns. Non-relational databases often have a more flexible schema, allowing for dynamic indexing based on changing data structures.
-
Performance Trade-offs: Both types of databases face trade-offs between read and write performance. Relational databases might see a more significant impact on write operations due to multiple indexes. Non-relational databases, depending on their design, might optimize for write-heavy operations but could require different indexing strategies to ensure efficient reads.
-
Index Types: Relational databases commonly use B-trees, hash indexes, and bitmap indexes. Non-relational databases may use a variety of structures, including hash indexes, inverted indexes, and custom indexing strategies tailored to their specific data models.
Conclusion
Indexing is a powerful tool for optimizing database performance, but the strategies and implementations differ between relational and non-relational databases. Understanding these differences can help you choose the right database and indexing strategy for your application’s needs. Relational databases offer robust indexing features suited to structured data, while non-relational databases provide flexible indexing options for varied and evolving data models.
By considering the type of database and its indexing capabilities, you can enhance both the efficiency and performance of your data retrieval operations.